Lorsqu’on veut connaître les caractéristiques ou les opinions d’une
population, on a souvent recours à un échantillon. Cependant, comme le hasard
s’en mêle parfois, toute estimation faite à partir d’un échantillon
comporte une marge d’erreur plus ou moins grande. Nous verrons dans
ce chapitre comment évaluer cette marge d’erreur. On dira, par exemple,
que 79 % des Canadiens trouvent les tribunaux trop complaisants envers
les criminels (avec une marge d’erreur de plus ou moins 3 %, 19 fois
sur 20), ou que la taille moyenne des Américains de sexe masculin
âgés est comprise entre 174,7 cm et 175,7 cm (avec un niveau de confiance
de 95 %). Les deux premières sections de ce chapitre seront consacrées
à ce genre d’estimation.
Les échantillons peuvent aussi nous permettre de vérifier des hypothèses.
Peut-on affirmer, par exemple, que les criminels ont une capacité
crânienne inférieure à la moyenne, ou encore que les jeunes filles
ont une estime de soi inférieure à celle des jeunes garçons? Là encore,
puisque nous utilisons des échantillons, le hasard peut nous jouer
des tours. Nous verrons, dans les sections 3 et 4 du présent chapitre,
comment évaluer les chances de nous tromper en acceptant ou en rejetant
une hypothèse.
Pour nous aider dans notre démarche, nous utiliserons des outils familiers :
la moyenne, l’écart type et la courbe de distribution normale. Comme
il arrive parfois que les échantillons soient très petits, surtout
lorsqu’on étudie un groupe d’individus bien particulier, nous aurons
parfois recours à une autre distribution, bien connue des chercheurs
en laboratoire : la distribution de Student. Nous pourrons alors, sans
grand effort supplémentaire, soutirer plus d’information à l’échantillon.
Au terme de ce chapitre, vous devriez être en mesure de répondre aux questions suivantes :
Comment peut-on, à partir d’un échantillon, estimer la proportion d’individus possédant telle ou telle caractéristique dans une population donnée?
Comment peut-on, à partir d’un échantillon, estimer la valeur moyenne d’une caractéristique des membres d’une population?
Quelle est, lorsque l’on fait une estimation, la marge d’erreur possible correspondant à un niveau de confiance donné?
Comment peut-on vérifier une hypothèse fondée sur une caractéristique d’une population?
Comment peut-on vérifier une hypothèse fondée sur la comparaison d’une même caractéristique dans deux populations différentes?
1. ESTIMER DES PROPORTIONS
Grâce à un échantillon, nous commencerons par déterminer comment la population se répartit entre les diverses catégories d’une
variable. Il nous restera ensuite à évaluer les risques de faire ainsi
une estimation éloignée de la réalité.
1.1. Calcul de l’erreur type
Le sondage dont il est question dans le tableau 8.1 porte
sur l’opinion des Canadiens concernant la criminalité dans les années 1990. On constate
qu’une forte majorité de gens trouvent que les tribunaux manquent
de sévérité envers les criminels. En guise de consolation pour le
Québec, signalons que, selon la même enquête, ceux qui croient que
le taux de criminalité violente est en augmentation dans leur localité
s’avèrent moins nombreux à Montréal (45 %) qu’à Toronto (57 %). À vous de vérifier si les gens d’aujourd’hui sont aussi sévères que leurs aînés.
Nous voulons savoir dans quelle mesure les caractéristiques
de l’échantillon observé risquent d’être éloignées de celles de la
population que nous cherchons à connaître.
Pour savoir que 79 % de la population pense que les tribunaux
manquent de sévérité, les sondeurs ont observé un échantillon
de 1016 individus : ils ont fait une estimation. Il reste maintenant
à quantifier le degré de fiabilité (ou la marge d’erreur) de
cette estimation. C’est grâce au calcul de cette marge d’erreur que
le chercheur pourra déterminer si l’estimation est suffisamment précise
pour les besoins de sa recherche. Inversement, cette méthode permettra
d’évaluer la taille minimale de l’échantillon à observer compte tenu
de la précision recherchée.
Plus les échantillons sont grands, plus ils sont groupés
autour de leur valeur moyenne, ou, si l’on préfère, moins ils sont
dispersés.
Nous savons déjà un certain nombre de choses sur les échantillons
choisis au hasard. Il est possible de tirer d’une population une quantité
considérable d’échantillons. Certains de ces échantillons sont tout à fait représentatifs
de la population et d’autres s’en écartent plus ou moins. Lorsque
la taille des échantillons est suffisamment grande*, les différentes valeurs des paramètres
mesurés à partir de ces échantillons se distribuent selon le modèle
de la courbe normale : cela signifie que les échantillons correspondent,
en moyenne, à la population, et que l’on peut évaluer leur degré de
dispersion.
L’erreur type mesure le degré de dispersion des échantillons
autour de leur valeur moyenne.
Ce degré de dispersion des échantillons, qui se nomme erreur type,
est relativement facile à calculer et à interpréter (c’est le pendant
de l’écart type, vu au chapitre 3). Étant donné que l’erreur type
est très utilisée, notamment dans les sondages électoraux et les enquêtes
sociales, nous allons maintenant expliquer comment on doit s’en servir.
Essayons donc d’évaluer le degré de fiabilité de l’opinion exprimée
dans notre sondage du tableau 8.1 (« une proportion de 79 % des gens
croit que… ») en obtenant tout d’abord son erreur type. La formule
ci-dessous indique comment calculer l’erreur type et, malgré les apparences,
elle est plutôt simple.
La valeur p représente la proportion de la catégorie étudiée (estimée) et n
la taille de l’échantillon. En principe, on devrait utiliser les proportions
de la population, mais comme on ne connaît pas ces proportions on
doit se contenter de celles de l’échantillon.
On calcule d’abord le produit des deux proportions (celle
de la catégorie qui nous intéresse et celle des autres catégories
réunies). Pour simplifier, on peut écrire les deux proportions sous
leur forme décimale (la somme des deux proportions est alors égale
à 1).
Ici, les deux proportions sont respectivement 0,79 (« une proportion
de 79 % des gens croit que… ») et 0,21. Leur produit est égal à
0,79 x 0,21 = 0,1659
On divise le résultat obtenu par le nombre d’éléments dans
l’échantillon.
Ici, l’échantillon est de 1016 individus. On obtient donc 0,1659/1016 = 0,0001633
On calcule la racine carrée du résultat obtenu.
√(0,0001633) = 0,0128 = 1,28 % (disons 1,3 %)
1.2. Interprétation de la marge d’erreur
La véritable proportion se situe, avec un certain degré de
probabilité, dans un intervalle plus ou moins large autour de la valeur
estimée.
Rappelons que pour connaître l’opinion des gens sur la criminalité,
les sondeurs ont tiré au hasard un échantillon de 1016 individus.
Or, il existe une quantité innombrable d’échantillons de 1016 individus,
et certains d’entre eux peuvent, par malchance, donner des
résultats relativement éloignés de la réalité. Grâce à l’erreur
type que nous avons calculée, sa valeur s’établissant à 1,3 %, nous allons maintenant
pouvoir chiffrer avec précision ce que nous entendons par les expressions
relativement éloignés et par malchance.
Cette probabilité se nomme niveau de confiance et cet
intervalle se nomme intervalle de confiance.
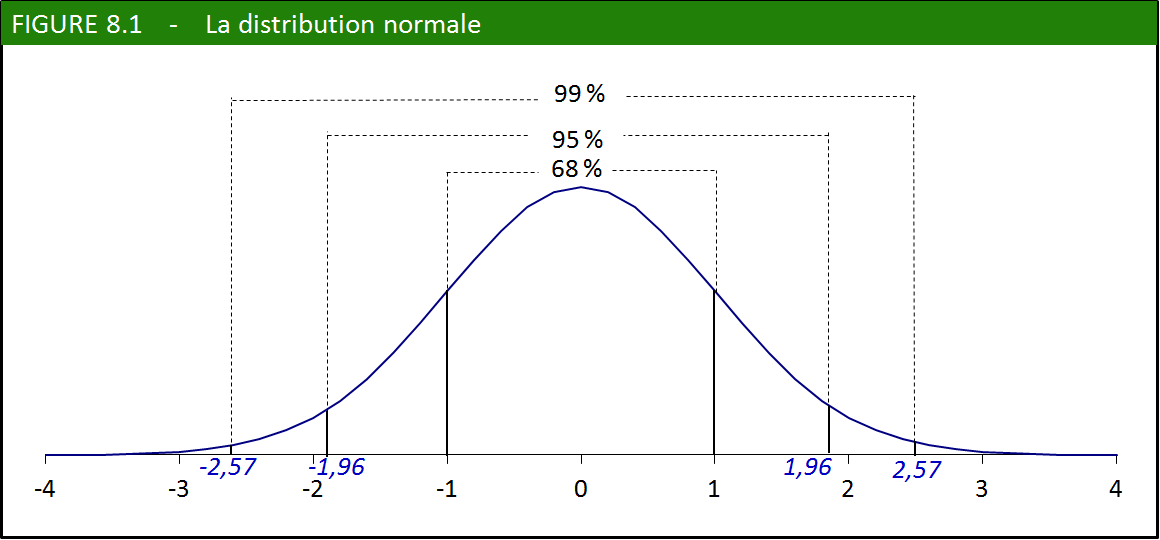
On se rappellera que, dans une distribution normale, 68 % (ou 0,68)
des éléments sont contenus à une distance de la moyenne ne dépassant
pas un écart type. Ici, les éléments sont les différents échantillons
que nous aurions pu tirer, et l’écart type de cet ensemble d’échantillons
s’appelle l’erreur type. Cela signifie que la proportion estimée grâce
à notre échantillon a 68 % de chances de ne pas s’écarter
de plus de 1,3 % de la proportion véritable.
En ratissant plus large, on augmente le niveau de confiance.
En pratique, on cherche à ratisser plus large de façon à faire des
affirmations un peu plus dignes de confiance. En augmentant le nombre
d’erreurs types à 1,96, on récupère 95 % de tous les échantillons (voir
la figure 8.1). De façon similaire, 99 % de tous les échantillons
sont compris entre -2,57 et +2,57 erreurs types. Dans la phrase précédente,
le premier chiffre est le niveau de confiance (99 %) et les deux
autres chiffres représentent l’intervalle de confiance (entre
-2,57 et 2,57).
Marge d’erreur à un niveau de confiance de 95 % = 1,96
× Erreur type
Marge d’erreur à un niveau de confiance de 99 % = 2,57
× Erreur type
Dans notre exemple, 1,96 erreur type représente environ 2,5 %
(on multiplie 1,96 par l’erreur type, soit 1,96 x 1,3 % = 2,5 %).
On peut donc dire, en simplifiant un peu, que dans 95 % des cas, la
proportion véritable se situera entre [79 % – 2,5 %] et [79 % + 2,5
%], ou entre 76,5 % et 81,5 %. Pour nous donner des allures de journaliste, nous dirions aussi que, 19 fois sur 20*, le résultat
peut varier au maximum de plus ou moins 2,5 %.
Étant donné que la proportion véritable est fixe et que
c’est en réalité notre estimation qui a des chances de coïncider plus
ou moins bien avec la réalité, on devrait plutôt dire que cet
intervalle de confiance (situé entre 76,5 % et 81,5 %) a 95 % de chances
de contenir la proportion véritable.
Dans le tableau 8.1 vu précédemment, il y a trois catégories d’opinion
et donc trois proportions. Étant donné que l’erreur type dépend de
la valeur de la proportion, chaque proportion possède sa propre erreur
type et sa propre marge d’erreur. Voilà qui est un peu fastidieux
pour le chercheur et ennuyeux pour le lecteur. Pourquoi ne pas mettre
les choses au pire en calculant l’erreur type d’une proportion de
50 % (c’est cette proportion qui donne l’erreur type la plus élevée)?
C’est ce que font la plupart des instituts de sondage lorsqu’ils publient
les résultats de leur enquête dans les journaux. Vérifions si c’est
bien le cas dans le tableau 8.1, où la marge d’erreur indiquée est
de 3,1 % pour le Canada.
Parfois, la marge d’erreur d’une estimation s’avère trop grande pour jouir de la moindre valeur. Lorsqu’une proportion estimée à 40 % possède une
erreur type de 1 %, on ne peut pas se plaindre. Par contre, une estimation
de 1 % avec une erreur type de 0,5 % ne vaudrait pas grand-chose.
On comprend intuitivement que l’erreur type doit pouvoir être comparée
à la proportion à laquelle elle se rapporte : ce rapport s’appelle
le coefficient de variation.
Selon l’Enquête sociale générale de Statistique Canada, on comptait 20 525 000 parents adoptifs potentiels au Canada en 1990. On peut constater, par exemple, dans le tableau 8.2 que 4 447 000 d’entre eux n’avaient jamais vécu en couple et que 163 000 d’entre eux ont adopté au moins deux enfants au cours de l’année. Ces données ont été estimées à partir d’un échantillon portant sur 13 495 individus. On peut en déduire que chaque parent sondé représente 20 535 000/13 495 = 1521 parents dans la population. C’est ce qu’on appelle le poids d’échantillonnage (voir chapitre 7).
Dans le tableau 8.2, les estimations sont exprimées en quantités.
Mais il s’agit en réalité de proportions déguisées. Sur un total de
20 525 milliers de parents adoptifs potentiels, on compte, par exemple, 307 milliers
de parents qui ont été « mariés » une seule fois dans leur vie et qui ont
adopté un seul enfant : la proportion est de 307/20 525 = 1,5 %.
Calculons d’abord l’erreur type de cette proportion en utilisant la
formule vue un peu plus haut :
p = 1,5 % = 0,015 (la proportion des parents qui appartiennent à cette
catégorie)
(1 – p) = 0,985 (la proportion des parents qui n’appartiennent pas
à cette catégorie)
n = 13 495 (la taille de l’échantillon interrogé)
Erreur type = √[(0,015 x 0,985)/13 495] = √[0,0148/13 495] = 0,00105 = 0,105 %
Il ne nous reste plus qu’à calculer le coefficient de variation:
Lorsque le coefficient de variation dépasse 16 % (environ), on doit
interpréter les estimations avec prudence. Lorsque le coefficient
dépasse 33 %, les estimations n’ont tout bonnement aucune valeur.
Dans un tel cas en effet, et avec un niveau de confiance de 95 % (soit
1,96 erreur types… disons 2 pour simplifier), cela signifie que
les bornes de l’intervalle de confiance seraient situées à plus ou
moins 66 % (2 x 33 %) de l’estimation calculée. Si l’estimation était
de 3 %, par exemple, cela signifierait qu’un intervalle compris entre
1 % (soit 3 % – [66 % x 3 %] et 5 % (soit 3 % + [66 % x 3 %]) aurait
95 % de chance de contenir la proportion véritable. Ce serait beaucoup
trop vague.
EXERCICES 1
1. Échantillon réduit, erreur type accrue
Dans le tableau 8.1, l’institut Gallup évalue que, dans 95 % des cas,
la marge d’erreur ne dépasse pas 6 % pour les estimations concernant
le Québec.
a) Calculez l’erreur type pour le Québec en vous basant sur une proportion
de 50 %.
b) Vérifiez s’il est exact que, 19 fois sur 20, la marge d’erreur
ne dépasse pas 6 % pour le Québec.
2. Coefficient de variation
Calculez le coefficient de variation des résultats pour le Québec
à partir du tableau 8.1, toujours en vous basant sur une proportion
de 50 %.
2. ESTIMER UNE MOYENNE
Dans la section précédente, nous avons vu comment un échantillon permet,
avec un degré plus ou moins grand de fiabilité, d’estimer une proportion.
Nous avions par exemple estimé que 79 % des Canadiens trouvaient leurs
tribunaux trop indulgents, ou que 163 000 parents sur 20 525 000 (soit
7,9 % d’entre eux) avaient adopté deux enfants ou plus.
Un principe similaire s’applique lorsqu’il s’agit d’évaluer une moyenne
à partir d’un échantillon. Quelle est la taille moyenne des quinquagénaires
américains? Quel est le QI moyen des gens originaire de l’Extrême
Orient? Quel est le niveau moyen d’estime de soi des élèves québécois?
Dans tous ces cas, on pourrait faire une estimation de la moyenne
en observant un simple échantillon de la population.
La taille de l’échantillon n’a pas besoin d’être très grande, car tout
dépend du degré de précision désiré et des informations
dont on dispose sur la population sondée. Lorsque l’échantillon contient
au moins 30 éléments, on utilise encore une fois la distribution normale
pour calculer la marge d’erreur. Lorsque l’échantillon est plus petit
(ce qui est souvent le cas lors d’expériences de laboratoire), il
y a encore moyen de s’en sortir grâce à une autre distribution : le
t de Student.
Évidemment, il n’est pas interdit de travailler avec des échantillons
relativement grands. Nous allons voir dans l’exemple qui suit que
quelques centaines d’individus bien choisis nous permettent d’évaluer
avec une précision étonnante une caractéristique d’une population
de plusieurs millions de personnes.
2.1. Un gros échantillon : la taille des anciens combattants
En Europe, les Américains ont la réputation d’être un grand peuple (en centimètres),
surtout depuis un certain 6 juin 1944. Pour vérifier la chose et faire
des comparaisons, nous avons demandé aux fonctionnaires de Washington,
Québec et Ottawa de nous fournir des données précises. Les fonctionnaires
américains ont été les premiers à nous répondre, sans nous poser de questions
ni nous demander d’argent, et ils nous ont fourni toute une série de
paramètres sur la taille de leurs concitoyens par groupe d’âge et
origine ethnique : moyenne, écart type, mode, centiles, taille des
échantillons correspondants pour chaque groupe étudié. Une véritable
aubaine pour le chercheur en sciences humaines. Certains de ces paramètres sont
reproduits au tableau 8.3.
Ainsi, 690 hommes âgés de 45 à 54 ans ont été examinés à travers
le pays entre 1976 et 1980, ce qui a permis d’estimer la taille moyenne
des gens de ce groupe à 175,2 cm. Essayons d’établir la marge d’erreur
de cette estimation, en prenant un niveau de confiance de 0,95. Pour
cela, nous devons calculer, ici aussi, l’erreur type de la distribution
des moyennes d’échantillons.
En principe, on devrait utiliser l’écart type de la population (qui
est généralement inconnu) et le diviser par la racine carrée de n, soit le
nombre d’éléments dans l’échantillon. En pratique, on peut se contenter
de l’écart type de l’échantillon étudié, pourvu que l’échantillon
contienne au moins 30 éléments. On divise alors l’écart type par
√(n), comme dans la formule ci-dessus.
Pour calculer l’écart type d’un échantillon, on utilise
la formule étudiée au chapitre 3 à un détail près : on doit diviser
la somme des écarts au carré par (n – 1) et non par n comme c’est
le cas pour l’écart type d’une population (n représente le nombre
d’éléments dans l’échantillon). Dans l’exemple illustré ici, l’écart
type de l’échantillon avait déjà été calculé par ceux qui nous ont
communiqué les données. Nous donnerons un exemple détaillé du calcul
de l’écart type d’échantillon au tableau 8.4, un peu plus loin.
L’écart type de l’échantillon est de 6,6 cm. L’erreur type est donc
ici égale à 6,6/√(690) = 6,6/26,25 = 0,25 cm
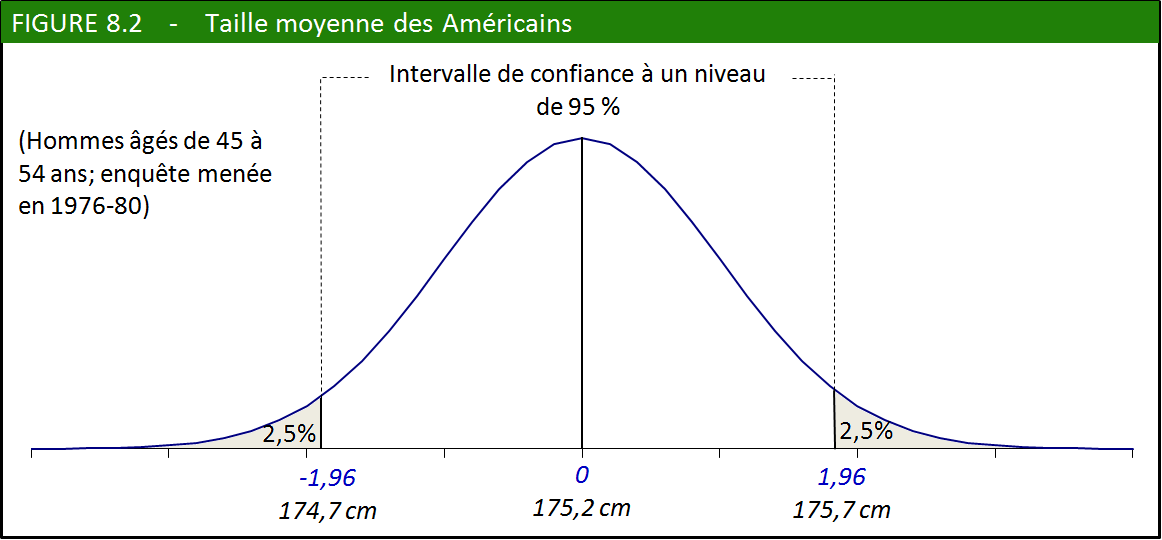
Notre intervalle de confiance, pour un niveau de 0,95, se situera
à 1,96 erreur type de part et d’autre de la moyenne (revoir la figure 8.1 si nécessaire).
Intervalle de confiance : entre [175,2 – (1,96 x 0,25)] et [175,2 + (1, 96 x 0, 25)]
entre (175,2 – 0,5) et (175,2 + 0,5)
entre 174,7 cm et 175,7 cm
Formulé autrement : la marge d’erreur est de 1,96 x 0,25, soit 0,5 cm.
Cela signifie qu’il y a 95 % de chances pour que l’intervalle compris
entre 174,7 cm et 175,7 cm contienne la véritable taille moyenne des
Américains de ce groupe-là. Dans la plupart des cas, on pourra considérer
que la moyenne estimée (à 175,2) est suffisamment précise. La figure
8.2 illustre ce résultat.
Étapes de l’estimation : échantillon contenant au moins 30 éléments tirés d’une population normale
1. Choisir un niveau de confiance.
2. Trouver la valeur correspondante à ce niveau de confiance dans la table de distribution normale.
3. Calculer l’erreur type de l’échantillon.
4. Calculer la marge d’erreur.
5. Calculer les deux bornes de l’intervalle de confiance
Nous allons maintenant estimer la taille moyenne des hommes de race
noire âgés de 45 à 54 ans en suivant les étapes que nous venons de
résumer. Cette fois, l’échantillon est beaucoup plus réduit (n = 62)
et la moyenne légèrement différente (174,2 cm), mais l’écart type
est identique, soit 6,6 cm (revoir le tableau 8.3).
1. Niveau de confiance : nous choisissons 0,95. Si jamais nous passons à côté de la cible 1 fois sur 20 (ou 0,05), ce ne sera pas tragique dans un cas semblable.
2. Valeur correspondante dans la table : en prenant une surface de 0,475 de part et d’autre de la moyenne, on obtient une surface totale de 0,95 (soit 0,475 x 2); cela correspond à une valeur de 1,96 dans la table de distribution normale.
3. Erreur type = Écart type/√(n) = 174,2 cm/√(62) = 6,6 cm/7,87 = 0,84 cm.
4. Marge d’erreur : 1,96 x 0,84 cm = 1,6 cm.
5. Intervalle de confiance : entre [174,2 – 1,6] et [174,2 + 1,6], soit entre 172,6 et 175,8 cm.
On constate que cet intervalle de confiance est plus large que le
précédent. Cet échantillon, parce que plus petit, est moins fiable
que le précédent.
On constate également que la borne supérieure de cet intervalle
dépasse la borne équivalente pour l’ensemble de la population (qui
était de 175,7 cm). Si, en apparence, la moyenne est moins élevée
pour les Noirs que pour l’ensemble, il est toujours possible que cet
écart observé soit l’effet du hasard d’échantillonnage.
2.2. Un petit échantillon : le prix des abonnements
Les spécialistes de la publicité connaissent fort bien les
ficelles quantitatives du métier.
Depuis que les produits sont devenus plus difficiles à vendre qu’à
fabriquer, les agences de mise en marché ont inventé toutes sortes
de formules pour écouler disques, livres et revues. La maison Publisher
Clearing House propose par exemple plus d’une centaine d’abonnements
annuels à prix réduit sous la forme d’un dépliant coloré accompagné
d’une feuille de timbres. Le client n’a qu’à détacher le timbre correspondant
à la revue désirée et à coller ce timbre sur le bon de commande pour
bénéficier d’une réduction substantielle. Voilà pour le consommateur
une façon amusante d’avoir l’impression d’économiser. Pour
renforcer cette perception, il va de soi que le montant de la réduction
est imprimé en plus gros caractères que le prix effectif de l’abonnement.
C’est sans doute la raison pour laquelle les réductions sont libellées
en dollars (et non en proportion) : ainsi, l’œil est automatiquement
attiré vers les réductions les plus grandes et, par le fait même,
vers les revues les plus chères. Notons enfin que l’entreprise dont
il est question n’a pas jugé bon de mélanger les réductions en dollars
(« 25 $ de rabais sur 499 $ ») avec des réductions exprimées en proportions (« 25
% de rabais sur 2 $ ») comme c’est souvent le cas dans les dépliants publicitaires.
Nous avons essayé d’estimer le prix moyen d’un abonnement annuel,
à l’aide d’un petit échantillon de 12 éléments (voir le tableau 8.4). Étant donné que la population totale n’est pas très élevée
(il y a 103 abonnements annuels offerts dans le dépliant), il aurait
été facile de l’observer directement sans passer par un échantillon,
avouons-le. Cependant, notre unique but est ici d’illustrer la façon d’estimer
une moyenne avec un petit échantillon.
Le procédé d’estimation est le même que dans le cas précédent (la
taille moyenne des anciens combattants), sauf que la table de la
distribution normale (utilisée à l’étape 3) doit être remplacée par
la table de la distribution de Student, mieux adaptée aux petits échantillons.
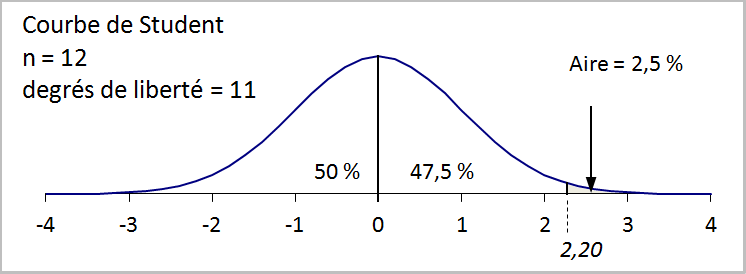
La table de distribution de Student (voir la figure 8.3) fonctionne
un peu à l’envers de la table de distribution normale, puisqu’elle
donne, pour une surface donnée, le seuil à atteindre (appelé valeur
t de Student). Supposons que le niveau de confiance choisi soit de
0,95. On sélectionnera dans la table la colonne 0,025, ce qui éliminera
une surface (et une probabilité) de 0, 025 (ou 2,5 %) sur chacune
des deux extrémités de la courbe. Il nous reste maintenant à identifier
la bonne ligne dans la table (degrés de liberté). C’est la taille
de l’échantillon qui détermine le nombre de degrés de liberté, selon
la formule suivante :
Degrés de liberté (dans une estimation de moyenne) = n – 1
où n est la taille de l’échantillon observé.
Dans notre exemple, la valeur t de Student pour une surface de 0,025
et 11 degrés de liberté est de 2,20.
Étapes de l’estimation : échantillon contenant moins de 30 éléments tirés d’une population normale
1. Choisir un niveau de confiance.
2. Calculer le nombre de degrés de liberté.
3. Trouver la valeur correspondante à ce niveau de confiance et au nombre de degrés de liberté dans la table de distribution de Student.
4. Calculer l’erreur type de l’échantillon.
5. Calculer la marge d’erreur.
6. Calculer les deux bornes de l’intervalle de confiance.
Avant de suivre ces étapes, il nous faut déterminer nous-mêmes la
moyenne et l’écart type (ces deux chiffres nous étaient déjà fournis
dans l’exemple précédent). Deux méthodes s’offrent à nous. Nous pouvons
faire le calcul complet ou utiliser les fonctions d’un chiffrier électronique.
Le tableau 8.4 illustre ces deux méthodes et donne une moyenne
de 24,56 $ et un écart type de 5,19 $ pour notre échantillon de 12
éléments.
Niveau de confiance : nous choisissons à nouveau 0,95, c’est-à-dire que nous rejetons 0,025 de chaque côté.
Nombre de degrés de liberté : 12 – 1 = 11.
Valeur t de Student correspondant à une surface de 0,025 et 11 degrés de liberté (voir la figure 8.3) : 2,20.
Erreur type : 5,19 $/√(12) = 1,50 $.
Marge d’erreur : Valeur t de Student x Erreur type = 2,20 x 1,50 $ = 3,30 $.
Bornes de l’intervalle de confiance : entre [24,56 – 3,30] et [24,56 + 3,30], soit entre 21,26 $ et 27,30 $. Cela signifie qu’il y a 95 % de chances que le véritable prix moyen de l’abonnement soit compris entre 21,26 $ et 27,30 $. C’est plutôt vague, mais c’est mieux que rien!
Comme on peut le constater, il est difficile de faire une estimation
précise dans ce cas-ci, car deux facteurs jouent simultanément contre
nous : l’échantillon est très petit et l’écart type est relativement
grand. Nous pourrions contourner la difficulté en augmentant la taille
de l’échantillon. C’est ce que nous avons fait en sélectionnant 36
éléments au hasard, ce qui nous donne une moyenne de 22,30 $ et un
écart type de 4,63 $.
Erreur type : 4,63 $/√(36) = 0,77 $.
Niveau de confiance : toujours 0,95.
Nombre de degrés de liberté : 36 – 1 = 35.
Valeur dans la table de Student (colonne 0,025 et ligne 35) : 2,03. Notons que lorsque la taille de l’échantillon dépasse 30, la distribution de Student commence à ressembler sérieusement à la distribution normale : nous aurions obtenu une valeur de 1,96 (très proche de 2,03) si nous avions utilisé la table normale pour un niveau de confiance de 0,95. C’est la raison pour laquelle on peut généralement se contenter d’utiliser la distribution normale lorsque la taille de l’échantillon atteint ou dépasse 30 éléments.
Marge d’erreur : 2,03 x 0,77 $ = 1,56 $.
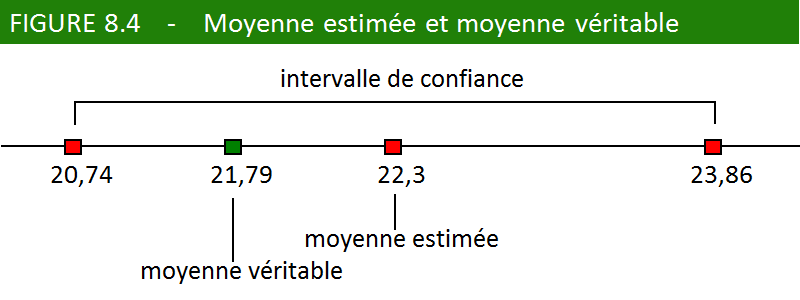
Intervalle de confiance : entre [22,30 $ – 1,56 $] et [22,30 $ + 1,56 $], soit entre 20,74 $ et 23,86 $.
À titre d’information, notez que la véritable moyenne (que nous
avons calculée à partir de l’ensemble de la population) se situe à
21,79 $ par abonnement. La figure 8.4 illustre la portée de notre
dernière estimation. La moyenne véritable se trouve bien à l’intérieur
de notre intervalle de confiance (il y avait seulement une chance
sur 20 pour que cet intervalle ne contienne pas la moyenne), tout en étant
quelque peu éloignée de la moyenne estimée à partir de notre échantillon
(un écart de 0,51 $ les sépare).
EXERCICES 2
1. Les petits actuels sont-ils des ex-grands?
Il paraît que l’on rapetisse avec l’âge. D’autre part, on a observé
que la taille moyenne des soldats américains augmente d’une génération
à l’autre : 171 cm pendant la Première Guerre mondiale, 174 cm pendant
la Deuxième, 175 cm pendant la Guerre du Vietnam et 176 cm pendant
la Guerre du Golfe.
a) En vous servant des données du tableau 8.3, calculez l’intervalle
de confiance pour les hommes âgés de 18 à 24 ans et pour les hommes
âgés de 65 à 74 ans, avec un niveau de confiance de 0,95.
b) Même question avec un niveau de confiance de 0,99.
c) Commentez les écarts de taille entre les deux groupes d’âge.
2. Les abonnés absents
Nous avons tiré au hasard un nouvel échantillon de 12 abonnements
de la société Publisher Clearing house (voir le tableau 8.4). Les
prix de l’abonnement annuel sont respectivement les suivants : 29,97
$; 11,25 $; 21,97 $; 23,97 $; 21,95 $; 18,97 $; 22,97 $; 21,95 $; 19,67
$; 20,98 $; 24,97 $ et 27,97 $.
a) Calculez la moyenne du prix de l’abonnement.
b) Calculez l’écart type (d’échantillon).
c) Calculez l’erreur type.
d) Calculez l’intervalle de confiance, pour un niveau de confiance
de 0,95.
3. VÉRIFIER UNE HYPOTHÈSE À L’AIDE D’UN ÉCHANTILLON
Dans la section précédente, nous avons montré dans quelle mesure un
échantillon peut nous aider à mieux connaître la population dont il
est issu. Nous avons utilisé la courbe normale pour estimer, avec
une marge d’erreur plus ou moins grande, un paramètre d’une population
comme, par exemple, la taille moyenne des Américains. Lorsque l’échantillon
était plus petit, comme dans le cas du prix moyen des abonnements,
nous avons remplacé la courbe normale par la courbe de Student.
Ici, la démarche est un peu différente, quoiqu’elle fasse appel aux
mêmes outils. L’échantillon n’est plus utilisé pour estimer un paramètre,
mais plutôt pour vérifier une hypothèse concernant la population.
Nous nous demanderons par exemple comment un échantillon peut nous
permettre d’affirmer avec un certain degré de certitude, que le QI
des Asiatiques est plus élevé que la moyenne, ou que le volume crânien
des criminels ne diffère pas de celui de la population en général.
Plus l’échantillon est petit, plus le hasard peut nous jouer des tours,
mais il ne tient qu’à nous de garder le contrôle de la situation en
évaluant le degré de risque encouru lorsque nous posons une hypothèse.
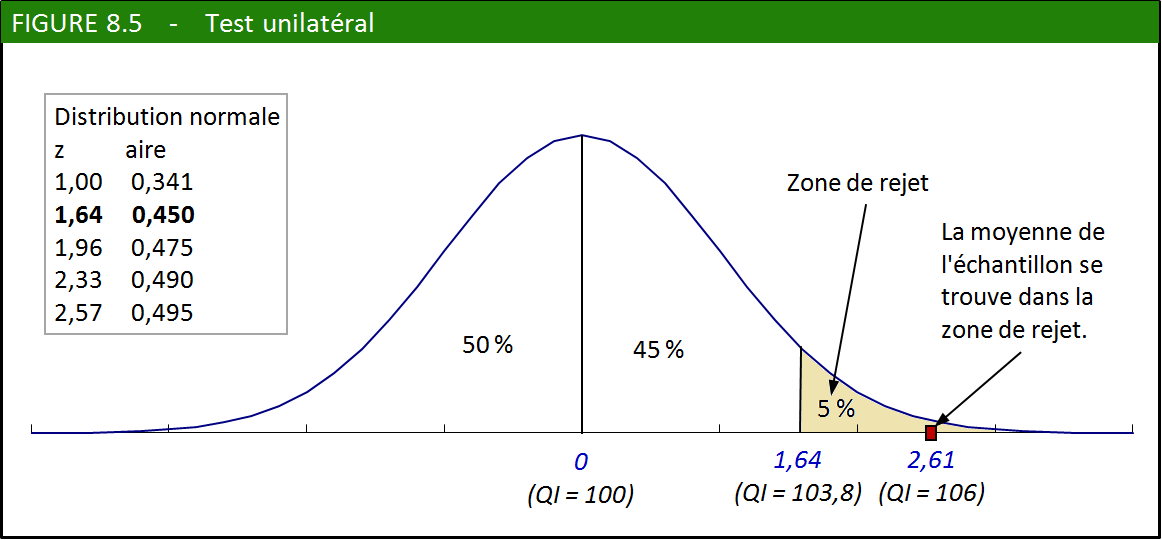
3.1. Un test unilatéral : le QI des Asiatiques
Le QI (quotient intellectuel) est un indicateur controversé. On ne
sait pas exactement ce qu’il mesure : l’inné ou l’acquis? L’intelligence
en général ou certaines aptitudes particulières choisies arbitrairement?
Chose certaine, il est abusif d’évaluer l’intelligence d’un individu
en se basant sur le QI du groupe auquel il appartient : ce n’est pas
parce que le QI moyen de votre classe est faible cette année que vous
êtes moins intelligent que d’habitude. Cette mise en garde étant faite,
cherchons maintenant à satisfaire notre curiosité : les Asiatiques
ont-ils, en moyenne, un QI supérieur à celui que l’on retrouve dans
la population en général?
Une enquête qui porte sur la jeunesse américaine à travers les décennies
(National Longitudinal Survey of Youth) nous fournit quelques chiffres.
Un échantillon de 42 jeunes Américains originaires d’Extrême-Orient
montre que ces derniers ont un QI moyen de 106 (contre 100 pour l’ensemble
de la population, en 1990). La même enquête indique d’autre part que
le QI est distribué de façon normale avec un écart type de 15. L’écart
est-il suffisamment grand, compte tenu de la faible taille de l’échantillon,
pour qu’on ne puisse l’attribuer au hasard?
Étapes du test d’hypothèse sur une moyenne
L’hypothèse selon laquelle la moyenne tirée de l’échantillon
est la même que celle de la population s’appelle l’hypothèse nulle.
1. Formuler l’hypothèse. Généralement, l’hypothèse est formulée de
façon positive : le QI moyen des Asiatiques (les gens de l’échantillon)
est le même que le QI moyen de la population. Il faut aussi formuler
une solution de rechange au cas où notre hypothèse serait rejetée :
le QI moyen des Asiatiques est supérieur à celui de la population.
L’hypothèse à vérifier est appelée hypothèse nulle. La solution
de rechange, qui aurait pu prendre une autre forme, est appelée hypothèse
alternative.
Le seuil de signification représente le risque de rejeter
à tort l’hypothèse nulle.
2. Quel est le seuil de signification désiré? Autrement dit,
quel est le risque de rejeter à tort une hypothèse vraie? Ici, nous
pouvons par exemple décider de prendre le risque maximum de nous tromper
1 fois sur 20 (ou 0,05).
La valeur critique (il peut y en avoir deux) délimite la zone de rejet de l’hypothèse.
3. Trouver, à partir de la table de la distribution normale, le seuil
à ne pas dépasser pour accepter l’hypothèse. Ici, le seuil, ou valeur critique est de +1,64 erreur type (voir la figure 8.5 ci-après).
Dans la table normale, on cherchera la valeur correspondant à 0,45,
ce qui nous permettra d’englober 0,05 dans la zone de rejet.
L’écart réduit représente le nombre d’erreurs types qui
séparent la moyenne de l’échantillon de celle de la population.
4. Calculer l’écart réduit entre la moyenne estimée et la moyenne
de la population. Pour cela, il faut diviser l’écart entre les deux
moyennes (celle de l’échantillon moins celle de la population) par
l’erreur type (dont la formule a été vue dans la section précédente).
Ici, Erreur type = Écart type/√(n) = 15/√(42) = 2,3 unités de QI.
L’écart réduit est donc de (106 – 100)/2,3 = 2,61.
5. Accepter ou rejeter l’hypothèse après avoir comparé l’écart réduit
(calculé à l’étape 4) à la valeur critique (calculée à l’étape 3).
Ici, nous sommes dans la zone de rejet, puisque l’écart réduit (2,61)
dépasse la valeur critique (1,64). Cet écart est assez grand pour
que nous puissions rejeter l’hypothèse nulle (« le QI moyen des Asiatiques
est le même que celui de la population ») et accepter l’hypothèse de
rechange (« le QI moyen des Asiatiques est supérieur à celui de la
population »).
En acceptant l’hypothèse alternative, nous courons encore le risque
de nous tromper. Cependant, ce risque est inférieur aux limites que nous
nous sommes fixées à l’étape 2 (soit 0,05 ou 5 %). La figure 8.5 illustre
ce résultat.
Lorsque la taille de l’échantillon est inférieure à 30,
il est toujours possible d’effectuer un test d’hypothèse, à condition
toutefois que la population soit distribuée de façon normale. On remplacera
alors, dans l’étape 3, la table de distribution normale par la table
de distribution de Student, comme nous l’avons fait dans la section
précédente pour l’estimation de moyenne.
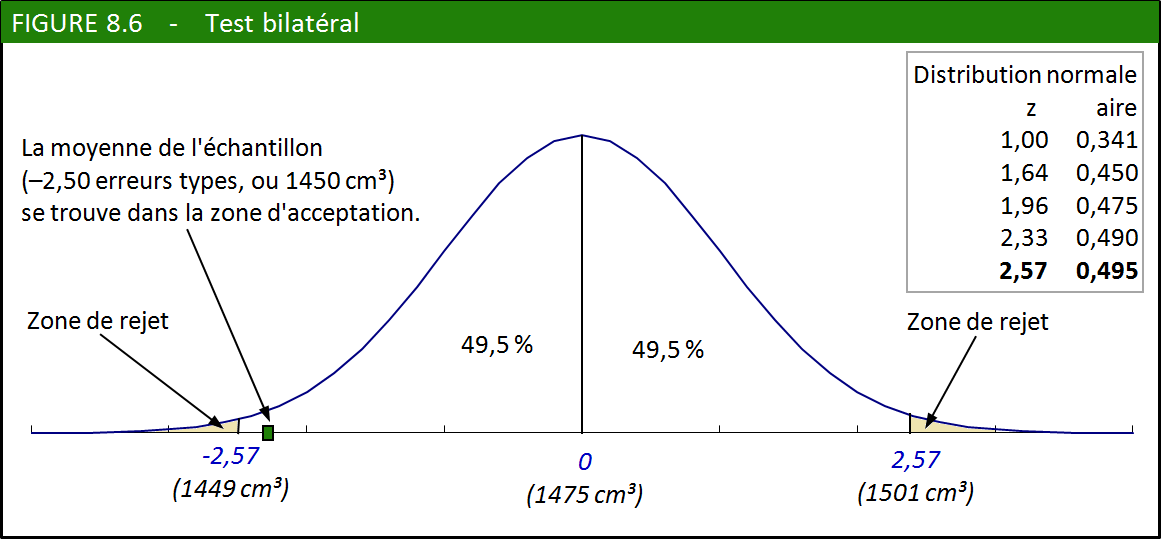
3.2. Un test bilatéral : les crânes de Lombroso
Encore un sujet délicat…
Non, il ne s’agit pas d’une nouvelle marque de pâtes. À la fin
du XIXe siècle, Cesare Lombroso, dans le cadre d’une vaste étude, a
mesuré la capacité crânienne de 121 criminels pour voir si elle différait
de ce qu’on pouvait observer dans la population en général. Même si
certaines de ses conclusions ont été remises en question par la suite,
Lombroso peut être considéré comme un des fondateurs de la criminologie
moderne.
La capacité crânienne des 121 têtes criminelles était en moyenne de
1450 cm3, tandis que celle de la population était de 1475 cm3
avec un écart type de 110 cm3.
Lors d’un test d’hypothèse bilatéral, il y a deux zones de rejets. Cela signifie que la moyenne de l’échantillon peut aussi bien être inférieure que supérieure à la moyenne de la population.
1. Formuler l’hypothèse nulle : « la capacité crânienne moyenne des
criminels est la même que celle de la population ». Hypothèse alternative :
« la capacité crânienne moyenne des criminels est différente de celle
de la population ». Comparez cette hypothèse alternative avec celle
que nous avions formulée dans l’exemple précédent. Nous voulions savoir
si le QI moyen des Asiatiques était supérieur (ou bien égal)
à celui de la population, car rien ne nous laissait croire que ce
QI puisse être inférieur. Cette fois, nous n’avons pas d’idée préconçue
sur le sujet. Si jamais la capacité crânienne de criminels devait
être différente de celle de la population, rien ne nous laisse présupposer
qu’elle soit supérieure ou inférieure. Il faudra alors établir deux
valeurs critiques (une valeur minimum et une valeur maximum), d’où
le nom de test bilatéral.
2. Seuil de signification : nous décidons de prendre moins de risque
que dans l’exemple précédent, étant donnée la gravité de la question,
aussi nous choisissons un seuil de signification de 0,01
3. Valeurs critiques : puisque le test est bilatéral, il y a deux zones
de rejets (une à gauche du minimum et une à droite du maximum) totalisant
en tout 0,005 + 0,005 = 0,01 des possibilités. Les valeurs critiques
correspondantes sont de –2,57 et +2,57 erreurs types (voir la figure
8.6 ci-après).
4. Erreur type de l’échantillon = 110/√(121) = 110/11 = 10 cm3.
Écart réduit = (1450 – 1475)/10 = –25/10 = –2,5.
On pourrait aussi convertir les valeurs critiques dans l’unité de
mesure de la variable, on obtient respectivement de 1475 – (2,57 x
10) et 1475 + (2,57 x 10) : la zone d’acceptation est comprise entre
1449 et 1501 cm3. Dans ce dernier calcul, 1475 représente la
moyenne, 2,57 la valeur critique trouvée dans la table normale et
10 l’erreur type.
5. Décision : l’écart réduit se trouve dans la zone de non-rejet. En
d’autres mots, la capacité crânienne des criminels se trouve à l’intérieur
des valeurs critiques, quoique de justesse. Jusqu’à nouvel ordre, et
tant que nous n’aurons pas de données plus convaincantes, nous acceptons
l’hypothèse nulle (« la capacité crânienne moyenne des criminels est
la même que celle de la population »).
EXERCICES 3
1. Encore le QI
Selon l’enquête longitudinale sur la jeunesse américaine de 1990 dont
il a été question dans cette section, le QI moyen des Américains de
confession juive serait de 114,5. Ce chiffre a été obtenu à partir
d’un échantillon de 99 personnes. On sait d’autre part que l’écart
type de ce QI est de 15 pour l’ensemble de la population américaine.
Formulez une hypothèse et testez-la.
2. Encore des crânes
Une enquête d’Ernest Hooton basée sur un très large échantillon (1672
individus) indique que la circonférence de la tête des Bostoniens
blancs est en moyenne de 563 mm avec un écart type de 10 mm (Ernest
Hooton, The American Criminal, 1939). Un petit échantillon de 25 Bostoniens
membres d’une profession libérale révèlent que ces derniers ont une
circonférence moyenne de tête de 569,9 mm.
a) L’hypothèse nulle est la suivante : « la circonférence de la
tête des membres de l’échantillon observé ne diffère pas de façon
significative de celle de la population bostonienne en général ». Compte
tenu de cette formulation, testez l’hypothèse nulle avec un seuil
de signification de 0,05.
b) Même question avec un échantillon de 194 commerçants dont la circonférence
moyenne de tête est de 565,7.
4. TEST D’HYPOTHÈSE SUR DEUX MOYENNES
Dans la section précédente, nous voulions déterminer si un groupe
d’individus particulier avait des caractéristiques différentes de
celles de l’ensemble de la population. C’est pourquoi nous avons comparé
la moyenne obtenue grâce à un échantillon à la moyenne de la population.
Cette fois, nous allons comparer directement deux échantillons issus
de deux populations apparentées. Nous vérifierons par exemple si les
Américains de race noire sont plus grands (ou moins grands) que leurs compatriotes de race
blanche, ou si l’estime de soi est plus élevée au Québec chez les garçons
que chez les filles.
Nous utiliserons encore une fois des outils familiers : la courbe normale
(lorsque chacun des deux échantillons contient au moins 30 éléments)
et la courbe de Student (dans la situation contraire). Dans ce dernier
cas, il faut aussi que la population d’où sont extraits les échantillons
soit distribuée sur le modèle de la courbe normale.
4.1. Qui est le plus grand?
Selon l’enquête menée aux États-Unis dont nous avons parlé un peu plus
haut (voir tableau 8.3), les hommes de race blanche de ce pays mesurent en
moyenne 175,8 cm contre 175,5 cm pour les hommes de race noire. L’écart entre
ces deux moyennes est-il significatif? Même si la notion de race est
plus ou moins arbitraire*, ce genre de données peut avoir une réelle utilité pour un concepteur
de vêtement ou pour un chercheur qui étudie les conséquences de certaines
habitudes alimentaires. En sciences humaines, il ne faut jamais avoir
peur de mesurer. Ce qui compte, c’est de traiter les chiffres avec
rigueur et honnêteté.
Où l’on constate qu’il est facile de dire des âneries.
Il ne nous a pas été difficile de vérifier, à partir d’échantillons,
que la taille moyenne des Scandinaves dépasse celle des Philippins,
que celle des hommes dépasse celle des femmes et que celle des jeunes
gens de la génération actuelle dépasse celle de leur parent. Ces faits
établis, il est facile de les interpréter de façon erronée comme
dans les exemples suivants : « les Scandinaves sont supérieurs aux Philippins »,
« tu es une femme, je suis un homme, donc je suis plus grand que toi ».
On ne peut se baser sur les caractéristiques moyennes d’une
population pour déduire les caractéristiques d’un individu
en particulier. Ce serait faire preuve de bêtise encore plus que de
racisme. D’autre part, il ne faut pas confondre différent avec
inférieur. La première notion est vérifiable alors que la seconde
relève d’un jugement de valeur et non de la science. Enfin, si tout
le monde s’entend sur le concept de taille et sur la longueur des
centimètres, il en va autrement lorsqu’on mesure l’estime de soi,
le sentiment d’échec ou le quotient intellectuel. Dans ces derniers
cas, il faut alors redoubler de prudence, même si les enquêtes peuvent
fournir des résultats intéressants.
Étapes du test d’hypothèse sur deux moyennes
1. Formuler l’hypothèse de la façon suivante : la moyenne du premier
échantillon est égale à la moyenne du second échantillon (c’est l’hypothèse
nulle). Formuler aussi une hypothèse alternative qui sera
retenue si on rejette l’hypothèse nulle. L’hypothèse alternative peut
être formulée de trois façons selon les circonstances (c’est au chercheur
de choisir) :
– Moyenne 1 ≠ Moyenne 2 (test bilatéral)
– Moyenne 1 > Moyenne 2 (test unilatéral)
– Moyenne 1 < Moyenne 2 (test unilatéral).
2. Choisir un seuil de signification. Le hasard peut faire en sorte
que même si deux populations possèdent la même caractéristique moyenne,
les deux échantillons tirés soient si différents qu’ils nous font
rejeter l’hypothèse nulle. Quel est le risque, que nous sommes prêts
à prendre, de rejeter ainsi à tort l’hypothèse nulle?
3. Trouver, à partir de la table de distribution normale, la valeur critique (ou les valeurs critiques)qui nous permettra d’accepter ou de rejeter l’hypothèse
nulle. Pour cela, il faut tenir compte de l’hypothèse alternative :
le test est-il unilatéral ou bilatéral? (On note que ces trois premières
étapes sont les mêmes que pour le test d’hypothèse sur une moyenne
vu dans la section précédente.)
4. Calculer l’écart entre les deux moyennes (ou écart réduit)
de la façon suivante :
5. Décision : accepter l’hypothèse nulle si l’écart réduit que l’on
vient de calculer ne déborde pas de la valeur critique (ou des valeurs critiques) définie
à l’étape 3.
Application de la démarche à notre exemple
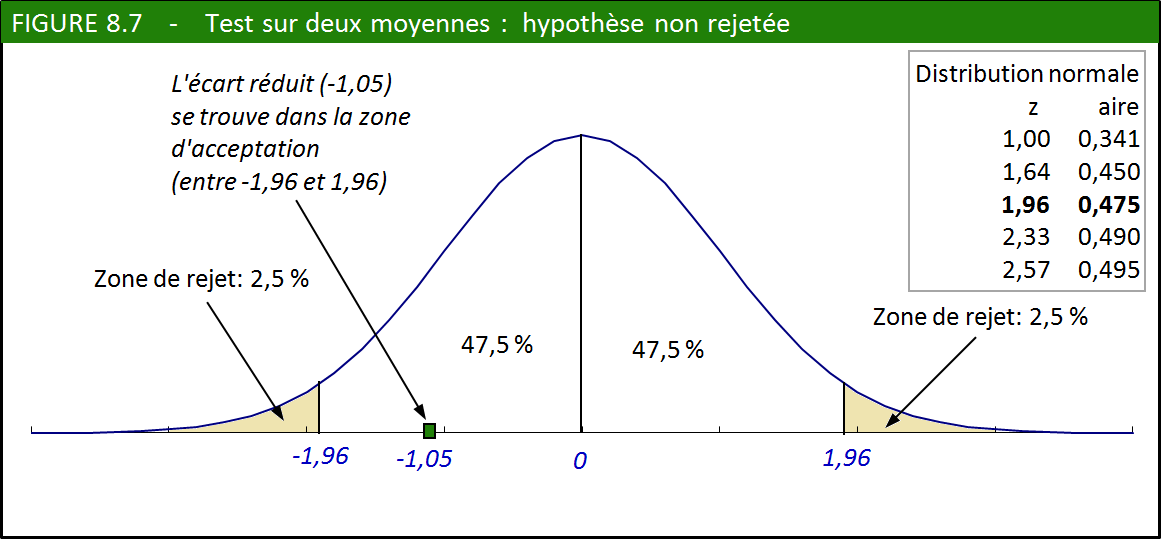
1. Hypothèse nulle : « La taille moyenne des Noirs est la même que celle des Blancs ». Hypothèse alternative : « La taille moyenne des Noirs est différente de celle des Blancs. »
2. Nous choisissons un seuil de signification de 0,05.
3. Il s’agit d’un test bilatéral. Les valeurs critiques pour un seuil de signification de 0,05 sont de –1,96 et +1,96. L’hypothèse nulle sera rejetée si l’écart réduit n’est pas compris à l’intérieur de ces limites.
4. Écart réduit :
nous reproduisons dans le tableau 8.5 ci-après les valeurs pertinentes du tableau 8.3 accompagnées de quelques données dérivées.
Numérateur de l’écart réduit : Moyenne1 – Moyenne2 = 175,5 – 175,8 = –0,3
Dénominateur de l’écart réduit :
√[(Écart type1²/n1) + (Écart type2²/n2)] = √[0,072 + 0,010] = √[0,082] = 0,286
Écart réduit = –0,3/0,286 = –1,05
5. Décision : l’écart entre les deux moyennes est trop faible pour
que nous rejetions l’hypothèse nulle. Jusqu’à preuve du contraire,
nous considérons que la taille moyenne des Noirs est égale à la taille
moyenne des Blancs (voir la figure 8.7).
4.2. L’estime de soi chez les garçons et les filles
Le corps humain se transforme rapidement lors de la puberté. La taille
augmente de 25 centimètres environ et le poids de 11 kilogrammes.
On change de voix, on change de visage, on se demande parfois si on
n’est pas dans le corps de quelqu’un d’autre. Les garçons gagnent
surtout en muscles et en os, tandis que les filles gagnent plutôt
en graisses. Ce changement d’image peut parfois diminuer ou accroître
l’estime de soi, selon qu’il répond ou non aux stéréotypes véhiculés
par la société. D’après une enquête menée au Québec*, il semble,
à première vue, que ce soit les filles qui sont le plus désavantagées
à cet égard (voir le tableau 8.6).
L’estime de soi a été mesurée à partir d’un questionnaire contenant
10 questions. Les 309 adolescents choisis, tous âgés de 11 à 18 ans,
devaient s’autoévaluer sur une échelle ordinale de 1 à 4. Les scores
pouvaient donc varier de 10 (faible estime de soi) à 40 (forte estime
de soi). En prime, nous avons ajouté sur le tableau le score du test
de croyances irrationnelles contenant 50 questions basées sur une
échelle ordinale de 1 à 6 (plus le score est bas, plus les croyances
irrationnelles sont grandes).
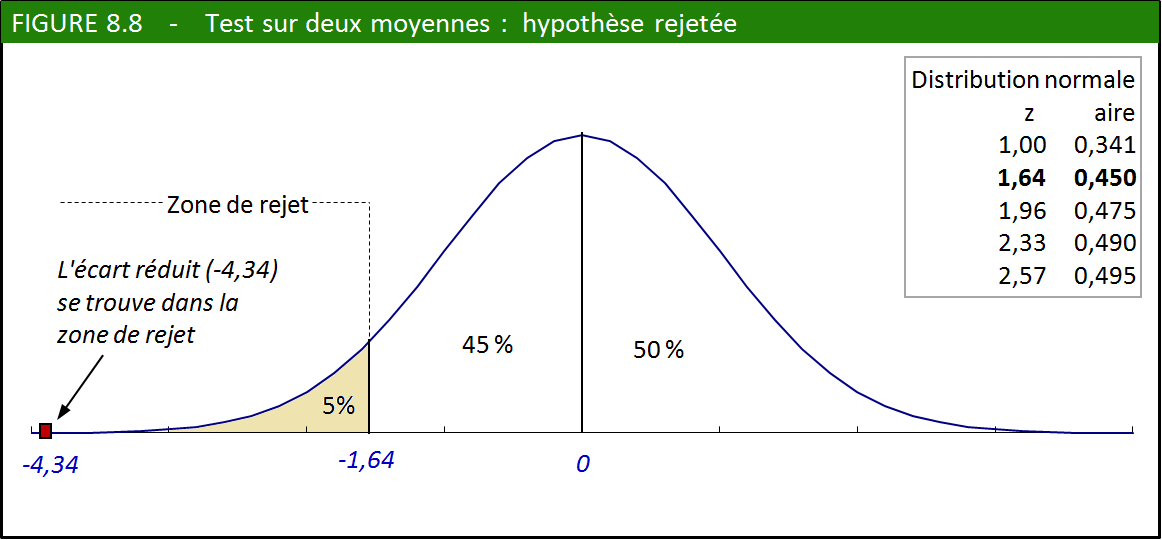
Le niveau d’estime de soi est-il le même chez les deux sexes? Essayons
de déterminer si l’écart entre le score moyen des garçons et des filles
est suffisant, compte tenu de la taille de l’échantillon, pour nous
permettre de rejeter cette hypothèse.
1. Hypothèse nulle : « Le niveau d’estime de soi est le même chez les
deux sexes ». Hypothèse alternative : « le niveau d’estime de soi est
plus faible chez les filles ».
2. Nous choisissons un seuil de signification de 0,95.
3. Nous avons affaire à un test unilatéral. La valeur critique, pour
un seuil de signification de 0,45, est de 1,64 dans la table normale.
Nous rejetterons donc l’hypothèse nulle si l’écart réduit que nous
calculerons à l’étape 4 est inférieur à –1,64 (voir la figure 8.8).
5. Décision : l’écart réduit (–4,34) est en deçà de la valeur critique
(–1,64). Nous rejetons l’hypothèse nulle.
EXERCICES 4
1. La pensée cartésienne? Moi, je n’y crois pas du tout.
En vous basant sur les données du tableau 8.6, testez l’hypothèse
suivante : le niveau de croyances irrationnelles est le même chez les
filles que chez les garçons.
EXERCICES SUPPLÉMENTAIRES
1. Un peu de vocabulaire
a) Identifiez dans la phrase suivante : le niveau de confiance, l’intervalle
de confiance et la marge d’erreur.
« Dans 95 % des cas, la proportion véritable des gens qui trouvent
les tribunaux trop peu sévères se situe entre [79 % – 2,5 %] et
[79 % + 2,5 %] (ou entre 76,5 % et 81,5 %). Pour faire plus journaliste,
on dira aussi que, 19 fois sur 20, le résultat peut varier au maximum
de plus ou moins 2,5 %. »
b) Identifiez, dans la phrase suivante : le seuil de signification,
les valeurs critiques. Formulez l’hypothèse nulle.
« Étant donné que l’écart réduit entre les deux moyennes estimées
dépasse 1,96 nous acceptons, avec une probabilité de nous tromper
inférieure à 5 %, l’hypothèse alternative qui veut que le QI moyen
des Quadrifluviens de l’Est soit différent de celui des Quadrifluviens
de l’Ouest. »
2. Des réfugiées politiques
Selon une étude publiée dans Santé mentale au Québec (vol.
21, no 1, printemps 1996, par Marta Yong), un échantillon de 94 Somaliennes
habitant la région d’Ottawa possède les caractéristiques suivantes :
L’âge des membres de l’échantillon varie de 18 à 50 ans avec une moyenne de 32,72 ans et un écart type de 8,27 ans;
Il y a 59 membres de l’échantillon qui sont mariées et 15 qui sont célibataires;
Il y a 44 % des membres de l’échantillon qui ont terminé leurs études secondaires et 29 % qui ont terminé des études universitaires (apparemment, il s’agit de deux catégories exclusives);
Il y a 49 % des membres de l’échantillon qui sont des résidentes permanentes et 25 % qui sont des citoyennes canadiennes;
Il y a 82 % des membres de l’échantillon qui ont immigré pour des raisons politiques et 13 % pour des raisons familiales.
(On suppose que l’échantillon est aléatoire.)
a) Identifiez les cinq variables dont il vient d’être question, indiquez
leur échelle de mesure, et indiquez leurs catégories s’il s’agit de
variables qualitatives.
b) Faites une estimation de l’âge moyen, pour un niveau de confiance
de 0,95.
c) Calculez la marge d’erreur des proportions, pour un niveau de confiance
de 0,95.
3. Test controversé sur des crânes
Le tableau 8.7 ci-après reproduit les données d’Ernest Hooton dont
il a été question dans ce chapitre.
a) Testez l’hypothèse selon laquelle les manœuvres ont la même circonférence
moyenne de tête que les membres de la population en général. (Utilisez
un seuil de signification de 0,05.)
b) Testez l’hypothèse selon laquelle la circonférence moyenne de la
tête des cadres est la même que celle des manœuvres. (Utilisez un
seuil de signification de 0,05.)
4. Laboratoire
a) À l’aide d’un chiffrier électronique, construisez un tableau
vous permettant de calculer automatiquement l’erreur type et le coefficient
de variation à partir des données pertinentes (vous pouvez vous inspirer
du tableau 8.2b).
5. Recherche : une taxe bien visible
Au Canada, les taxes de vente sont rarement incluses dans les prix
affichés. Les porte-parole gouvernementaux prétendent que cette manière
d’agir favorise la transparence en permettant aux consommateurs-contribuables
de « voir » les taxes. Vous devez faire une mini-enquête pour vérifier,
dans la mesure de vos moyens, si ce point correspond à la réalité.
Sélectionnez un échantillon de 30 à 50 personnes, en faisant en sorte,
si possible, qu’il soit relativement représentatif. Posez à ces personnes
des questions pour vérifier:
1) s’ils connaissent le taux de la taxe de vente fédérale (TPS) et
de la taxe provinciale pour divers produits (vêtements, aliments,
bière, livres, etc.);
2) s’ils ont tendance, de façon spontanée, à sous-estimer la
taxe lorsque les prix sont hauts et à la surestimer lorsque les prix
sont bas (ou l’inverse);
c) s’ils trouvent que la façon d’afficher les prix sans la taxe favorise
la transparence.
Identifiez les variables correspondant à chaque question et les échelles
de valeurs qui leur sont associées. Compilez les résultats. Calculez
la marge d’erreur des proportions (en faisant la supposition que votre
échantillon est aléatoire). Si vous le pouvez, faites des hypothèses
et vérifiez-les. Commentez les résultats.
6. Recherche : la taille des gens de votre entourage
Dans cette mini-enquête, vous allez essayer d’estimer la taille moyenne
des gens de votre entourage afin de la comparer à celle des Canadiens
en général (176,2 cm pour les hommes avec un écart type de 7 cm, et
161,9 cm pour les femmes avec un écart type de 6 cm).
a) Définissez la population dont vous voulez estimer la taille : lieu
(quartier, région, institution), sexe, âge (adultes, enfants de 12
ans), etc.
b) Sélectionnez un échantillon d’au moins 30 personnes appartenant
à la population que vous avez définie, en faisant en sorte, dans la
mesure du possible, que l’échantillon soit représentatif.
c) Faites une estimation de la taille moyenne de votre population
et calculez l’intervalle de confiance correspondant, pour un niveau
de confiance de 0,95.
d) Testez l’hypothèse suivante : « la taille moyenne de la population
observée est la même que celle de la population canadienne en général ».








 1.1. Calcul de l’erreur type
1.1. Calcul de l’erreur type